Trong vài năm trở lại đây, Machine Learning (Học Máy) đã trở thành một trong những từ khóa “hot” nhất trong lĩnh vực công nghệ thông tin. Không chỉ xuất hiện trong các bài viết chuyên ngành, Machine Learning còn được nhắc đến trong doanh nghiệp, tài chính, marketing và thậm chí cả đời sống hàng ngày.
Vậy Machine Learning là gì mà lại được quan tâm đến vậy?
Hiểu đơn giản, đây là một nhánh của Trí tuệ nhân tạo (AI), nơi máy tính được “dạy” cách tự học từ dữ liệu và tự cải thiện hiệu suất làm việc mà không cần con người lập trình chi tiết từng bước.
Trong bài viết này, SHOPVPS sẽ giúp bạn hiểu rõ khái niệm Machine Learning, các loại mô hình học máy phổ biến, cũng như ứng dụng thực tế của công nghệ này trong thế giới hiện đại.
Nếu bạn đang muốn khám phá cách máy móc có thể học, dự đoán và ra quyết định thông minh, hãy cùng bắt đầu hành trình tìm hiểu ngay bên dưới!

Machine Learning là gì?
Machine Learning (ML) — hay còn gọi là Học máy — là một nhánh quan trọng của Trí tuệ nhân tạo (AI), chuyên nghiên cứu cách để máy tính học hỏi từ dữ liệu và tự cải thiện hiệu năng mà không cần lập trình từng quy tắc tường minh. Thay vì viết tay mọi bước xử lý, người ta cung cấp cho mô hình những dữ liệu mẫu (training data) và thuật toán sẽ rút ra quy luật, từ đó dự đoán hoặc quyết định cho những tình huống mới.
Cách hoạt động cơ bản
Quá trình học máy gồm ba bước chính:
-
Thu thập dữ liệu: tập hợp dữ liệu đầu vào (ví dụ: ảnh, văn bản, bảng số liệu) và các nhãn (nếu có).
-
Huấn luyện mô hình: thuật toán tối ưu hóa các tham số để mô hình khớp tốt với dữ liệu huấn luyện.
-
Đánh giá & triển khai: kiểm tra mô hình trên dữ liệu chưa thấy trước (test data) và triển khai khi đạt yêu cầu. Mô hình tốt sẽ tổng quát hóa — tức là dự đoán chính xác với dữ liệu mới.
Phân loại bài toán phổ biến
Machine Learning thường giải quyết hai nhóm bài toán chính:
-
Dự đoán (Regression): ước lượng một giá trị liên tục — ví dụ dự đoán giá nhà, giá xe, hoặc doanh thu.
-
Phân loại (Classification): gán nhãn cho dữ liệu rời rạc — ví dụ nhận dạng chữ viết tay, phát hiện email rác, hoặc phân loại loại vật thể trong ảnh.
Ngoài ra còn có các bài toán khác như clustering (phân nhóm không cần nhãn), dimensionality reduction (giảm chiều dữ liệu), và reinforcement learning (học thông qua tương tác và nhận thưởng).
Ví dụ minh họa dễ hiểu
-
Hệ thống dự đoán giá căn hộ: dùng dữ liệu diện tích, vị trí, năm xây dựng để học và đưa ra dự đoán giá.
-
Nhận diện chữ viết: mô hình học từ hàng nghìn ảnh chữ viết có nhãn để phân loại chữ thành đúng ký tự.
-
Gợi ý sản phẩm: hệ thống học thói quen mua sắm để gợi ý sản phẩm phù hợp cho khách hàng.
Vai trò của dữ liệu và đánh giá
Chất lượng dữ liệu quyết định phần lớn hiệu quả mô hình. Dữ liệu nhiễu, thiếu hoặc lệch sẽ dẫn đến mô hình overfitting (khớp dữ liệu huấn luyện nhưng không tổng quát) hoặc bias (thiên lệch). Vì vậy, các bước tiền xử lý, chia tập huấn luyện/test, và đánh giá bằng các chỉ số (accuracy, precision, recall, MSE…) rất quan trọng.
Ứng dụng thực tế
Machine Learning hiện được ứng dụng rộng rãi trong:
-
Tài chính: chấm điểm tín dụng, dự đoán giá cổ phiếu (cẩn trọng với rủi ro).
-
Y tế: hỗ trợ chẩn đoán hình ảnh, dự đoán bệnh.
-
Marketing: phân tích khách hàng, cá nhân hóa quảng cáo.
-
Sản xuất & IoT: bảo trì dự đoán, tối ưu dây chuyền.
-
Giao thông: điều hướng, dự đoán tắc đường và lái tự động.
Quy trình làm việc với Machine Learning (Machine Learning Workflow)
Để xây dựng một mô hình Machine Learning (Học Máy) hoạt động hiệu quả, bạn không chỉ cần thuật toán mạnh, mà quan trọng hơn là phải tuân theo một quy trình làm việc rõ ràng, logic và có hệ thống — gọi là Machine Learning Workflow.
Quy trình này giúp bạn hiểu máy học vận hành như thế nào, từ khâu thu thập dữ liệu cho đến tối ưu mô hình và đánh giá kết quả.
Dưới đây là 5 bước cơ bản trong quy trình làm việc của Machine Learning:
1. Thu thập dữ liệu (Data Collection)
Đây là bước đầu tiên và quan trọng nhất. Mọi mô hình học máy đều cần một bộ dữ liệu (dataset) đủ lớn và chất lượng để “học” được các quy luật.
Dữ liệu có thể đến từ:
-
Các nguồn công khai (open datasets như Kaggle, UCI, Google Dataset Search)
-
Cơ sở dữ liệu nội bộ của doanh nghiệp
-
Hoặc tự thu thập thông qua API, cảm biến, hoặc khảo sát thực tế.
Lưu ý: Dữ liệu càng đầy đủ, chính xác và đa dạng, mô hình càng có khả năng học hiệu quả và tổng quát hóa tốt hơn.
2. Tiền xử lý dữ liệu (Data Preprocessing)
Trước khi đưa dữ liệu vào huấn luyện, ta cần “làm sạch” và “chuẩn hóa” dữ liệu.
Đây thường là bước tốn thời gian nhất, chiếm 70–80% tổng thời gian dự án.
Các công việc chính gồm:
-
Làm sạch dữ liệu: loại bỏ dữ liệu trùng lặp, bị thiếu hoặc nhiễu.
-
Chuẩn hóa và mã hóa dữ liệu: đưa dữ liệu về cùng định dạng, chuyển dữ liệu dạng chữ thành dạng số.
-
Trích xuất & chọn lọc đặc trưng (feature extraction/selection): xác định các thuộc tính quan trọng nhất ảnh hưởng đến kết quả học.
-
Chia tập dữ liệu: thường chia thành ba phần – training set, validation set, và test set để đảm bảo mô hình được đánh giá khách quan.
Dữ liệu “sạch” chính là nền tảng cho một mô hình tốt.
3. Huấn luyện mô hình (Model Training)
Ở bước này, ta sử dụng dữ liệu đã được xử lý để huấn luyện mô hình (training model).
Các thuật toán phổ biến có thể kể đến như: Linear Regression, Decision Tree, Random Forest, SVM, Neural Network, Deep Learning, v.v.
Quá trình huấn luyện giúp máy tính tìm ra mối quan hệ giữa đầu vào và đầu ra, học được các quy luật ẩn trong dữ liệu.
Tùy vào từng bài toán (dự đoán, phân loại, phân nhóm), ta sẽ lựa chọn thuật toán học có giám sát, không giám sát hoặc tăng cường (supervised, unsupervised, reinforcement learning) phù hợp.
4. Đánh giá mô hình (Model Evaluation)
Sau khi huấn luyện xong, cần kiểm tra độ chính xác và hiệu suất của mô hình bằng các chỉ số đo lường.
Một số thước đo phổ biến gồm:
-
Accuracy (độ chính xác)
-
Precision, Recall, F1-score (cho bài toán phân loại)
-
MSE, RMSE (cho bài toán hồi quy)
Nếu mô hình đạt độ chính xác từ 80% trở lên, thường được xem là hoạt động ổn định. Tuy nhiên, tùy lĩnh vực (như y tế, tài chính), yêu cầu có thể cao hơn.
5. Cải thiện và tối ưu mô hình (Model Improvement)
Không phải mô hình nào cũng đạt chuẩn ngay lần đầu. Nếu kết quả chưa tốt, ta cần quay lại các bước trước để tối ưu.
Các cách phổ biến để cải thiện mô hình gồm:
-
Thu thập nhiều dữ liệu hơn hoặc dữ liệu chất lượng hơn
-
Điều chỉnh tham số mô hình (hyperparameter tuning)
-
Thử thuật toán khác hoặc kết hợp nhiều mô hình (ensemble methods)
-
Cải thiện đặc trưng đầu vào (feature engineering)
Quá trình này thường lặp lại liên tục cho đến khi mô hình đạt hiệu suất mong muốn.
Phân loại Machine Learning (Các loại Học máy)
Machine Learning (Học máy) có thể được chia thành nhiều loại khác nhau tùy theo cách mô hình học từ dữ liệu. Trong thực tế, có rất nhiều phương pháp phân loại, nhưng phổ biến và được sử dụng rộng rãi nhất là hai nhóm chính:
-
Supervised Learning (Học có giám sát)
-
Unsupervised Learning (Học không giám sát)
Ngoài ra, còn có một số biến thể khác như:
-
Semi-Supervised Learning (Học bán giám sát)
-
Reinforcement Learning (Học tăng cường)
-
Deep Learning (Học sâu)
Tuy nhiên, trong phạm vi bài viết này, chúng ta sẽ tập trung vào hai loại cơ bản và nền tảng nhất trong Machine Learning: Học có giám sát và Học không giám sát.
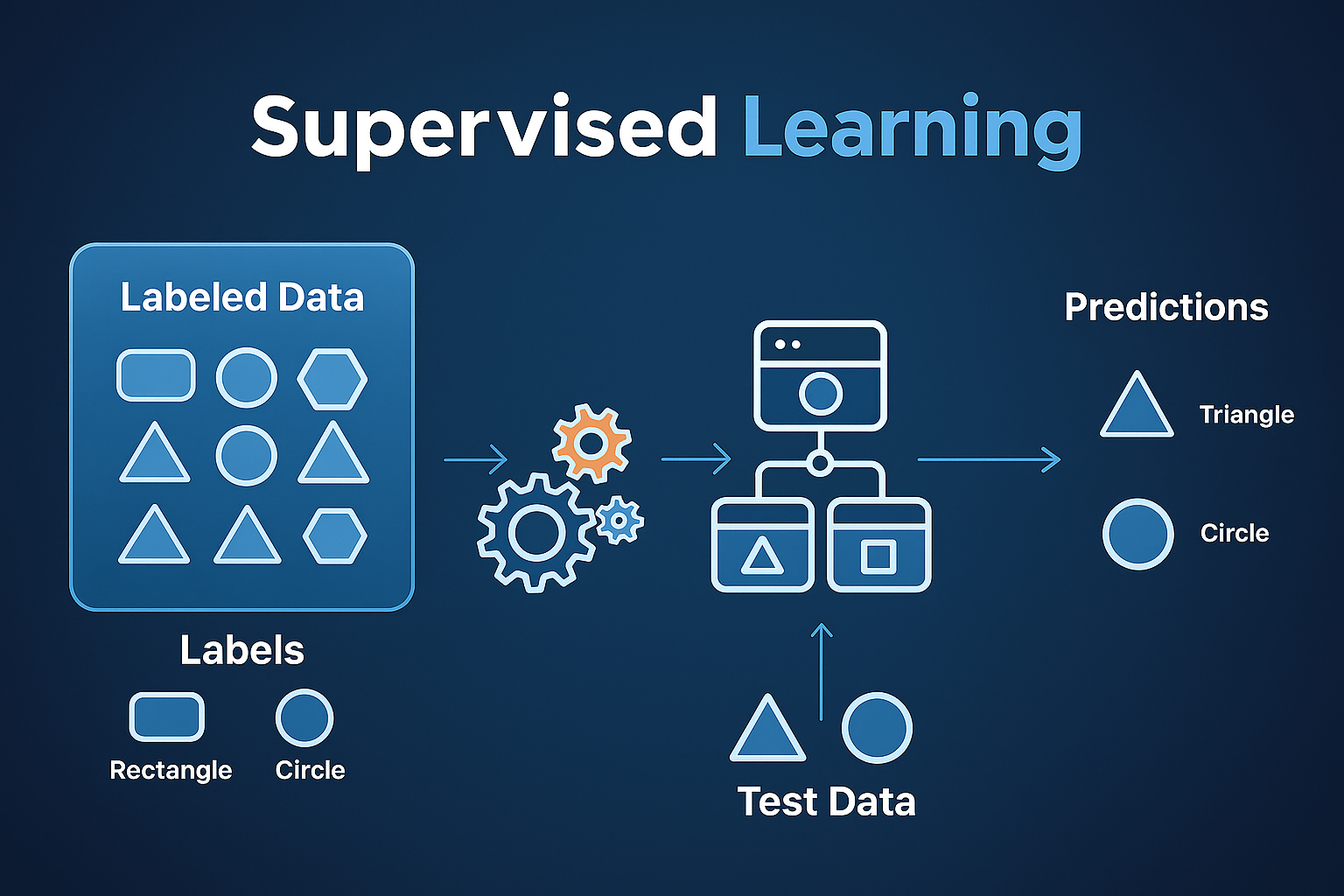
1. Supervised Learning – Học có giám sát
Supervised Learning là phương pháp mà trong đó dữ liệu huấn luyện đã được gán nhãn sẵn.
Điều này có nghĩa là với mỗi đầu vào (Input – X), chúng ta đã biết đầu ra tương ứng (Output – Y).
Mục tiêu của mô hình là học mối quan hệ giữa X và Y, từ đó có thể dự đoán kết quả mới khi gặp dữ liệu chưa từng thấy.
Ví dụ:
-
Dự đoán giá nhà dựa trên các yếu tố như diện tích, vị trí, số phòng ngủ, v.v.
-
Nhận diện email spam (1 = spam, 0 = không spam).
-
Phân loại hình ảnh mèo và chó.
Một số thuật toán phổ biến:
-
Linear Regression, Logistic Regression
-
Decision Tree, Random Forest
-
Support Vector Machine (SVM)
-
K-Nearest Neighbors (KNN)
-
Neural Network (Mạng nơ-ron)
Đặc điểm:
-
Cần dữ liệu đã được gán nhãn (labelled data).
-
Kết quả dự đoán thường rõ ràng và chính xác hơn so với học không giám sát.
-
Được ứng dụng mạnh trong các lĩnh vực như dự báo, phân loại, nhận dạng hình ảnh, phân tích rủi ro, v.v.
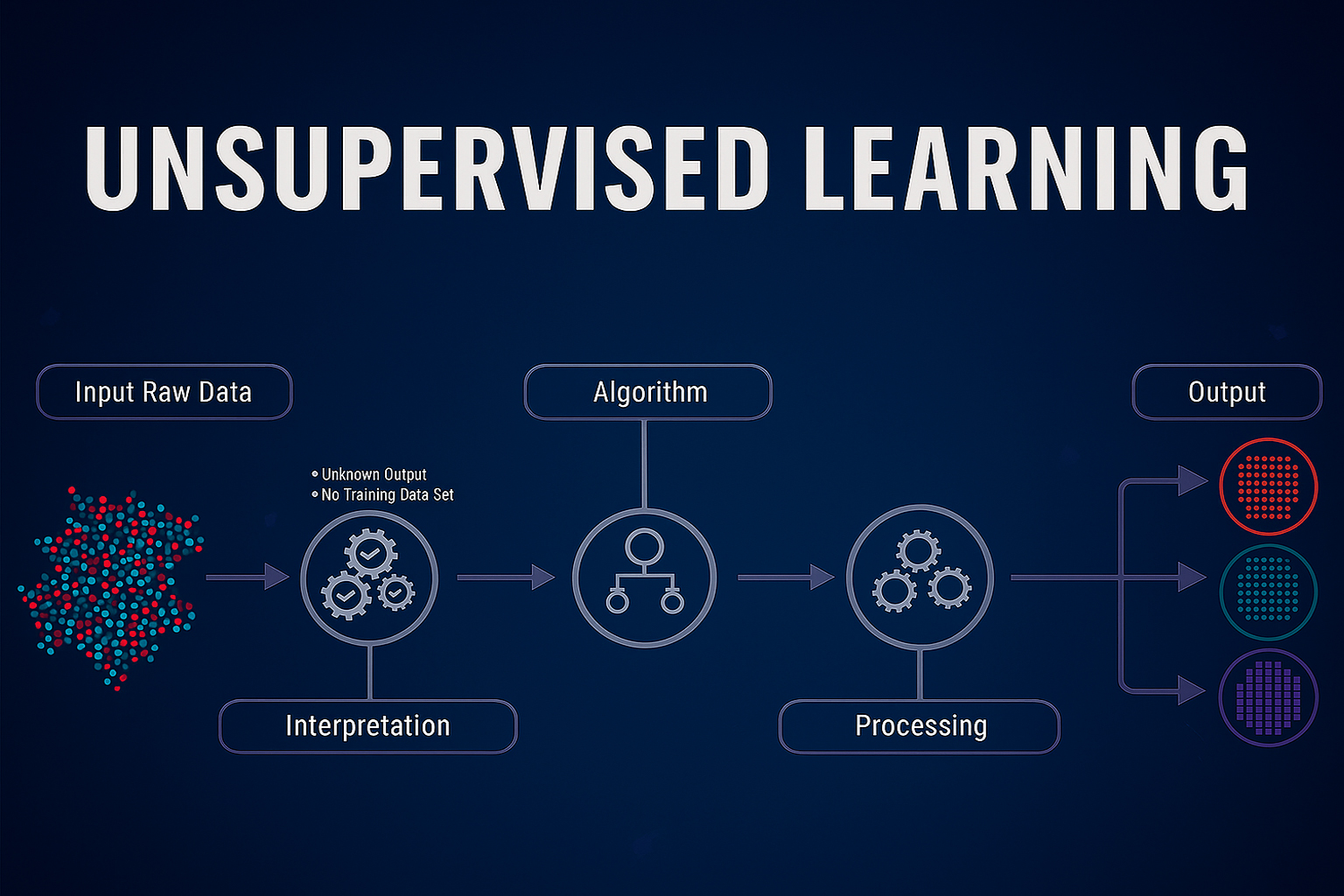
2. Unsupervised Learning – Học không giám sát
Trái ngược với học có giám sát, Unsupervised Learning làm việc với dữ liệu chưa được gán nhãn (unlabeled data).
Nhiệm vụ của mô hình là tự khám phá cấu trúc tiềm ẩn, mối quan hệ hoặc quy luật trong dữ liệu mà không có hướng dẫn cụ thể.
Ví dụ:
-
Phân nhóm khách hàng (Customer Segmentation) trong marketing.
-
Phát hiện gian lận trong dữ liệu tài chính.
-
Giảm số chiều dữ liệu (Dimensionality Reduction) để tối ưu tốc độ xử lý.
Các thuật toán phổ biến:
-
K-Means Clustering
-
Hierarchical Clustering
-
Principal Component Analysis (PCA)
-
Autoencoders
Đặc điểm:
-
Không cần dữ liệu có nhãn → tiết kiệm công sức gán nhãn thủ công.
-
Giúp khám phá ra mô hình hoặc nhóm dữ liệu tiềm ẩn mà con người khó nhận ra.
-
Tuy nhiên, độ chính xác khó đánh giá hơn vì không có “đáp án” đúng để so sánh.
Các loại khác trong Machine Learning (bổ sung)
Mặc dù hai loại trên là nền tảng, bạn cũng nên biết thêm về các hình thức học khác:
-
Semi-Supervised Learning (Học bán giám sát):
Kết hợp giữa học có giám sát và không giám sát — chỉ một phần dữ liệu có nhãn, phần còn lại không có. Phù hợp khi việc gán nhãn dữ liệu tốn kém hoặc khó khăn. -
Reinforcement Learning (Học tăng cường):
Mô hình học thông qua thử - sai. Nó nhận “thưởng” hoặc “phạt” dựa trên hành động, giúp cải thiện dần theo thời gian. Ứng dụng trong robot tự hành, trò chơi, và điều khiển tự động. -
Deep Learning (Học sâu):
Một nhánh nâng cao của Machine Learning, sử dụng mạng nơ-ron nhân tạo nhiều lớp (Neural Networks) để học dữ liệu phức tạp như hình ảnh, âm thanh, ngôn ngữ.
Có thể nói, Supervised Learning và Unsupervised Learning là nền tảng của toàn bộ lĩnh vực Machine Learning.
Một bên học từ dữ liệu có hướng dẫn, bên kia tự tìm hiểu cấu trúc dữ liệu, nhưng cả hai đều hướng đến mục tiêu chung: giúp máy tính học từ dữ liệu để đưa ra quyết định thông minh.

Một số khái niệm cơ bản trong Machine Learning
Để hiểu rõ cách Machine Learning (Học máy) hoạt động, bạn cần nắm vững một số thuật ngữ và khái niệm cơ bản thường xuyên xuất hiện trong quá trình xây dựng, huấn luyện và đánh giá mô hình.
Dưới đây là những khái niệm nền tảng quan trọng nhất mà bạn nên biết:
1. Dataset (Tập dữ liệu)
Dataset hay còn gọi là tập dữ liệu, là nguồn thông tin đầu vào mà máy học sẽ dựa vào để “học”.
Đây chính là tệp dữ liệu gốc (raw data) được thu thập ở bước Data Collection, có thể đến từ nhiều nguồn khác nhau như cảm biến, cơ sở dữ liệu, khảo sát, hay nguồn công khai.
Một dataset bao gồm nhiều điểm dữ liệu (data points), mỗi điểm thể hiện cho một đối tượng quan sát trong thế giới thực.
Ví dụ:
-
Dataset nhận diện khuôn mặt có thể chứa hàng nghìn ảnh gương mặt người.
-
Dataset dự đoán giá nhà có thể gồm diện tích, vị trí, số phòng, năm xây dựng, v.v.
2. Data Point (Điểm dữ liệu)
Data Point là một mẫu dữ liệu duy nhất trong tập dataset, thể hiện cho một quan sát cụ thể.
Mỗi điểm dữ liệu bao gồm nhiều đặc trưng (features) mô tả thông tin của đối tượng.
Các loại dữ liệu trong data point thường gồm:
-
Numerical Data (Dữ liệu số): Ví dụ: chiều cao, cân nặng, giá, tuổi, nhiệt độ.
-
Categorical Data (Dữ liệu phân loại): Ví dụ: giới tính (nam/nữ), màu sắc (đỏ/xanh), loại sản phẩm.
Trong bảng dữ liệu, mỗi dòng (row) chính là một data point, và mỗi cột (column) biểu thị một đặc trưng (feature) của điểm đó.
3. Training Data và Test Data
Khi xây dựng mô hình Machine Learning, dataset thường được chia thành hai phần chính:
-
Training Data (Dữ liệu huấn luyện):
Là phần dữ liệu được dùng để dạy cho mô hình “học” — giúp thuật toán tìm ra quy luật hoặc mối quan hệ giữa đầu vào và đầu ra. -
Test Data (Dữ liệu kiểm thử):
Là phần dữ liệu chưa từng được mô hình thấy trước đó, được dùng để kiểm tra độ chính xác và khả năng tổng quát hóa của mô hình sau khi huấn luyện.
Tỷ lệ chia dữ liệu phổ biến là 80% Training – 20% Testing hoặc 70% – 30%, tùy quy mô và tính chất của bài toán.
4. Feature Vector (Vector đặc trưng)
Feature Vector là cách biểu diễn một điểm dữ liệu (data point) dưới dạng vector số học nhiều chiều.
Mỗi chiều (dimension) trong vector tương ứng với một đặc trưng (feature) của dữ liệu.
Ví dụ:
Giả sử bạn có dữ liệu về căn hộ: [Diện tích, Số phòng, Giá thuê, Khoảng cách đến trung tâm]
→ Một vector đặc trưng có thể là:[80, 3, 15, 2] (đơn vị tương ứng: m², phòng, triệu đồng, km)
Hầu hết các mô hình Machine Learning (như Decision Tree, SVM, Neural Network...) chỉ làm việc được với dữ liệu dạng số, nên việc chuyển đổi dữ liệu thành vector đặc trưng là bắt buộc.
5. Model (Mô hình học máy)
Model (mô hình) là kết quả sau quá trình huấn luyện Machine Learning.
Nói cách khác, mô hình là công cụ “đã học” từ dữ liệu huấn luyện (training data) và có thể dự đoán hoặc ra quyết định khi gặp dữ liệu mới.
Ví dụ:
-
Mô hình dự đoán giá nhà có thể đưa ra giá cho căn hộ mới dựa trên thông tin đầu vào.
-
Mô hình phân loại email spam có thể nhận diện email rác trong hộp thư đến.
Mỗi loại mô hình (Linear Regression, Decision Tree, Neural Network, v.v.) có thuật toán và cách học khác nhau, nhưng đều hướng đến mục tiêu: tối ưu độ chính xác và khả năng dự đoán.
Ứng dụng của Machine Learning trong đời sống và công nghệ hiện nay
Trong thời đại Cách mạng công nghiệp 4.0, Machine Learning (Học máy) đã và đang trở thành một trong những công nghệ cốt lõi góp phần thay đổi cách con người làm việc, nghiên cứu và ra quyết định.
Từ việc dự đoán thời tiết, gợi ý phim ảnh, đến xe tự lái và phân tích tài chính, Machine Learning hiện diện ở hầu hết mọi lĩnh vực trong cuộc sống hiện đại.
1. Mạng máy tính và An ninh mạng
Machine Learning được ứng dụng mạnh trong việc phát hiện và ngăn chặn tấn công mạng.
Các hệ thống có thể phân tích lưu lượng truy cập, phát hiện hành vi bất thường, và tự động cảnh báo khi có dấu hiệu tấn công DDoS, mã độc hoặc truy cập trái phép.
Ví dụ: Hệ thống phát hiện xâm nhập (IDS/IPS) dùng Machine Learning để nhận biết hành vi đáng ngờ theo thời gian thực.
2. Khoa học vũ trụ
Trong nghiên cứu vũ trụ, Machine Learning giúp phân tích lượng dữ liệu khổng lồ thu thập từ kính thiên văn, vệ tinh, hoặc tàu thăm dò.
Các mô hình học máy hỗ trợ phát hiện hành tinh mới, xác định vật thể ngoài không gian, và tối ưu quỹ đạo bay cho tàu vũ trụ.
Ví dụ: NASA sử dụng Deep Learning để phát hiện hành tinh “ẩn” trong dữ liệu từ kính thiên văn Kepler.
3. Tài chính – Ngân hàng
Trong lĩnh vực tài chính, Machine Learning đóng vai trò trung tâm trong việc ra quyết định dựa trên dữ liệu.
Nó được sử dụng để:
-
Dự đoán xu hướng cổ phiếu
-
Phát hiện gian lận giao dịch
-
Xếp hạng tín dụng khách hàng
-
Tự động hóa quy trình xét duyệt khoản vay
Ví dụ: Các ngân hàng lớn như JPMorgan, HSBC, hoặc các ví điện tử đều ứng dụng ML trong phân tích rủi ro và gợi ý sản phẩm tài chính phù hợp.
4. Tự động hóa & Robotics
Machine Learning giúp robot và hệ thống tự động trở nên thông minh hơn — có khả năng học hỏi từ môi trường, tự điều chỉnh hành vi, và ra quyết định độc lập.
Ứng dụng phổ biến: Robot sản xuất, xe tự hành (self-driving cars), drone giao hàng hoặc robot dọn dẹp tự động.
5. Sinh học & Y học
Trong ngành y sinh, ML giúp phân tích hình ảnh y tế (X-quang, MRI), dự đoán bệnh lý, thiết kế thuốc, và tìm hiểu cấu trúc gen.
Ví dụ: Hệ thống DeepMind (Google) có thể phát hiện sớm các dấu hiệu bệnh võng mạc tiểu đường hoặc ung thư với độ chính xác cao hơn bác sĩ trong nhiều trường hợp.
6. Nông nghiệp thông minh
ML giúp nông dân dự đoán thời tiết, năng suất mùa vụ, và phát hiện sâu bệnh trên cây trồng thông qua ảnh chụp từ drone hoặc cảm biến.
Ví dụ: Các hệ thống nông nghiệp AI có thể dự đoán thời điểm tưới nước, bón phân hoặc thu hoạch tối ưu, giúp tiết kiệm chi phí và tăng sản lượng.
7. Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP)
Machine Learning là nền tảng của các ứng dụng hiểu và xử lý ngôn ngữ con người như:
-
Trợ lý ảo (ChatGPT, Google Assistant, Siri)
-
Dịch ngôn ngữ tự động (Google Translate)
-
Phân tích cảm xúc (sentiment analysis) trên mạng xã hội
Ví dụ: ML giúp chatbot có thể hiểu ngữ cảnh câu hỏi và phản hồi tự nhiên giống con người.
8. Thị giác máy tính (Computer Vision)
Machine Learning cho phép máy tính nhận dạng hình ảnh, video, khuôn mặt, vật thể, chữ viết tay…
Ví dụ: Hệ thống an ninh nhận diện khuôn mặt, ứng dụng chụp ảnh tự động lấy nét hoặc xe tự lái phân tích hình ảnh giao thông trong thời gian thực.
9. Quảng cáo & Marketing
Các nền tảng quảng cáo như Google, Facebook, TikTok đều sử dụng ML để phân tích hành vi người dùng, từ đó hiển thị quảng cáo phù hợp nhất với sở thích, vị trí, và lịch sử tìm kiếm của từng người.
Ví dụ: Bạn tìm kiếm “laptop”, ngay sau đó các quảng cáo liên quan sẽ xuất hiện — đó chính là nhờ thuật toán học máy.
10. Tìm kiếm & Khai thác thông tin
ML giúp tối ưu công cụ tìm kiếm, phân loại thông tin và trích xuất dữ liệu quan trọng từ hàng triệu nguồn khác nhau.
Ví dụ: Google Search, YouTube hay Amazon đều sử dụng ML để gợi ý kết quả cá nhân hóa dựa trên thói quen của người dùng.
Ví dụ thực tế: Dự báo thời tiết
Trước đây, việc dự báo thời tiết phụ thuộc vào các mô hình toán học phức tạp và khả năng tính toán giới hạn của con người.
Ngày nay, nhờ Machine Learning, máy tính có thể phân tích hàng tỷ dữ liệu khí tượng trong quá khứ, phát hiện mẫu biến động thời tiết, và dự đoán xu hướng trong tương lai với độ chính xác cao vượt trội.

Lời kết
Machine Learning không chỉ là một xu hướng công nghệ nhất thời, mà là nền tảng cốt lõi đang định hình tương lai của thế giới số. Nhờ khả năng phân tích dữ liệu, nhận diện mẫu và tự cải thiện, học máy đang giúp con người giải quyết những bài toán phức tạp mà trước đây gần như không thể thực hiện.
Từ dự báo thời tiết, phân tích tài chính, nhận diện hình ảnh, chăm sóc y tế, cho đến trí tuệ nhân tạo trong đời sống hằng ngày, Machine Learning đã chứng minh sức mạnh vượt trội trong việc tự động hóa và ra quyết định thông minh.
Trong kỷ nguyên AI và dữ liệu lớn (Big Data), việc hiểu rõ Machine Learning là gì và cách nó hoạt động không chỉ giúp bạn nắm bắt công nghệ, mà còn mở ra cơ hội phát triển sự nghiệp bền vững trong tương lai.
Dù bạn là người mới học lập trình, chuyên viên dữ liệu, hay người đam mê công nghệ, việc đầu tư thời gian để hiểu và ứng dụng Machine Learning sẽ là bước đi đúng đắn để đón đầu làn sóng chuyển đổi số đang diễn ra mạnh mẽ.
Trong tương lai gần, Machine Learning sẽ không chỉ là công nghệ của các “ông lớn” như Google, Amazon hay Microsoft, mà còn trở thành công cụ phổ biến trong mọi doanh nghiệp và lĩnh vực đời sống.
Chính vì vậy, hiểu và học Machine Learning hôm nay chính là đầu tư cho chính tương lai của bạn trong kỷ nguyên trí tuệ nhân tạo.

