Dataset là gì? Đây là một trong những thuật ngữ cốt lõi mà bất kỳ ai bước chân vào lĩnh vực học máy (Machine Learning) đều phải nắm vững. Trong thời đại dữ liệu lên ngôi, dataset trở thành “nhiên liệu” giúp các mô hình AI học hỏi, đưa ra dự đoán và cải thiện độ chính xác theo thời gian. Tuy nhiên, không phải ai cũng hiểu rõ dataset bao gồm những gì, vai trò của nó ra sao và cần lựa chọn dataset như thế nào cho từng dự án cụ thể.
Trong bài viết này, SHOPVPS sẽ giúp bạn khám phá từ A–Z về dataset: khái niệm, cấu trúc, phân loại và lý do vì sao nó quyết định đến thành công của một mô hình học máy. Nếu bạn đang tìm kiếm kiến thức nền tảng nhưng dễ hiểu, trực quan và đúng trọng tâm, thì đây chính là hướng dẫn dành cho bạn.

Khái niệm Dataset
Dataset là một tập hợp dữ liệu được thu thập, sắp xếp và lưu trữ theo một cấu trúc nhất định, thường xuất hiện dưới dạng bảng, ma trận hoặc các định dạng như CSV, Excel, JSON. Trong đó, mỗi hàng đại diện cho một đối tượng hoặc một mẫu dữ liệu cụ thể, còn mỗi cột tương ứng với từng thuộc tính (feature) mô tả đối tượng đó. Nhờ vậy, dataset đóng vai trò như “bản đồ thông tin” giúp con người và máy tính hiểu được mối quan hệ giữa các dữ liệu.
Trong lĩnh vực machine learning, dataset chính là nguồn dữ liệu dùng để huấn luyện mô hình. Mô hình sẽ học từ những mẫu dữ liệu này để nhận diện quy luật, đưa ra dự đoán và thực hiện các nhiệm vụ như phân loại, nhận dạng, gợi ý hay dự báo. Việc chuẩn bị một dataset chất lượng, đủ lớn và phù hợp với mục tiêu dự án được xem là bước quan trọng nhất, bởi nó ảnh hưởng trực tiếp đến độ chính xác và khả năng hoạt động của mô hình.
Có thể nói, dataset là nền tảng không thể thiếu trong quá trình xây dựng ứng dụng AI, phân tích dữ liệu và phát triển hệ thống thông minh. Đây cũng là yếu tố thúc đẩy mạnh mẽ sự tiến bộ của các công nghệ xử lý dữ liệu và phần mềm hiện đại ngày nay.
Tại sao cần dataset trong học máy?
Trong học máy (Machine Learning), dataset chính là yếu tố cốt lõi quyết định sự thành công của mô hình. Mọi thuật toán, dù phức tạp hay tiên tiến đến đâu, cũng đều cần dữ liệu để “học”. Không có dữ liệu, AI không thể rút ra quy luật, không thể đưa ra dự đoán và càng không thể tự cải thiện theo thời gian. Vì vậy, dataset được xem như “nhiên liệu” giúp mô hình vận hành và phát triển.
Một mô hình học máy chỉ thực sự hiệu quả khi được đào tạo bằng dữ liệu chất lượng, đa dạng và đủ lớn. Nếu dataset thiếu tính đại diện, không sạch hoặc bị gắn nhãn sai, mô hình dù mạnh mẽ đến đâu cũng cho ra kết quả sai lệch, dẫn đến dự án AI thất bại. Điều này cho thấy: chất lượng dataset quan trọng hơn cả thuật toán.
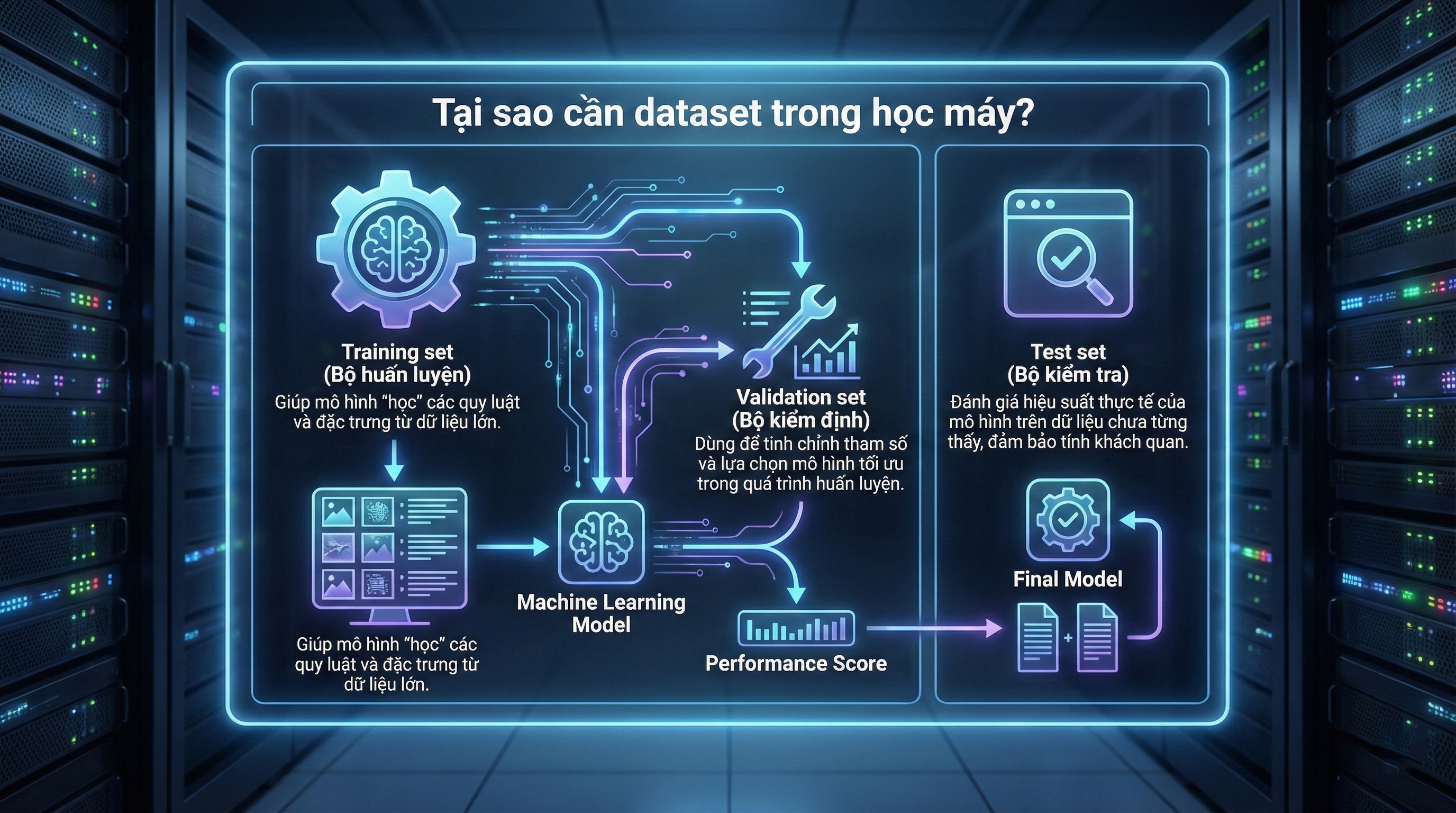
Trong quy trình xây dựng mô hình AI, người dùng phải làm việc với dữ liệu ở hầu hết mọi giai đoạn—từ thu thập, làm sạch, gắn nhãn, phân loại đến kiểm thử. Để mô hình học máy hoạt động đúng, dữ liệu thường được chia thành ba nhóm chính:
-
Training set: dùng để huấn luyện mô hình.
-
Validation set: giúp tinh chỉnh tham số, chọn mô hình tối ưu.
-
Test set: dùng để đánh giá khả năng dự đoán thực tế của mô hình.
Trong đó, validation set đặc biệt quan trọng vì nó giúp kiểm soát hiện tượng overfitting và hỗ trợ chọn ra phiên bản mô hình cuối cùng hoạt động tốt nhất.
Mặc dù nhiều người nghĩ rằng chỉ cần thu thập dữ liệu là đủ, nhưng thực tế phức tạp hơn nhiều. Việc làm sạch, gắn nhãn và chuẩn hóa dữ liệu thường tiêu tốn phần lớn thời gian của dự án AI. Để tạo ra một dataset chất lượng cao, người phát triển cần đảm bảo dữ liệu phải chính xác, đầy đủ, có tính đại diện cho thực tế và phản ánh đúng môi trường mà mô hình sẽ hoạt động.
Nói cách khác, nếu thuật toán là bộ não của AI thì dataset chính là đôi mắt và trải nghiệm sống của nó. Không có dataset tốt, AI không thể “nhìn thấy” thế giới để học hỏi đúng đắn.
Các loại dataset được sử dụng trong học máy
Trong học máy (Machine Learning), dữ liệu thường được chia thành ba nhóm chính, mỗi nhóm đảm nhận một vai trò khác nhau trong quá trình huấn luyện và đánh giá mô hình. Việc phân tách đúng và sử dụng hợp lý các loại dataset này giúp mô hình hoạt động ổn định, chính xác và hạn chế sai lệch.
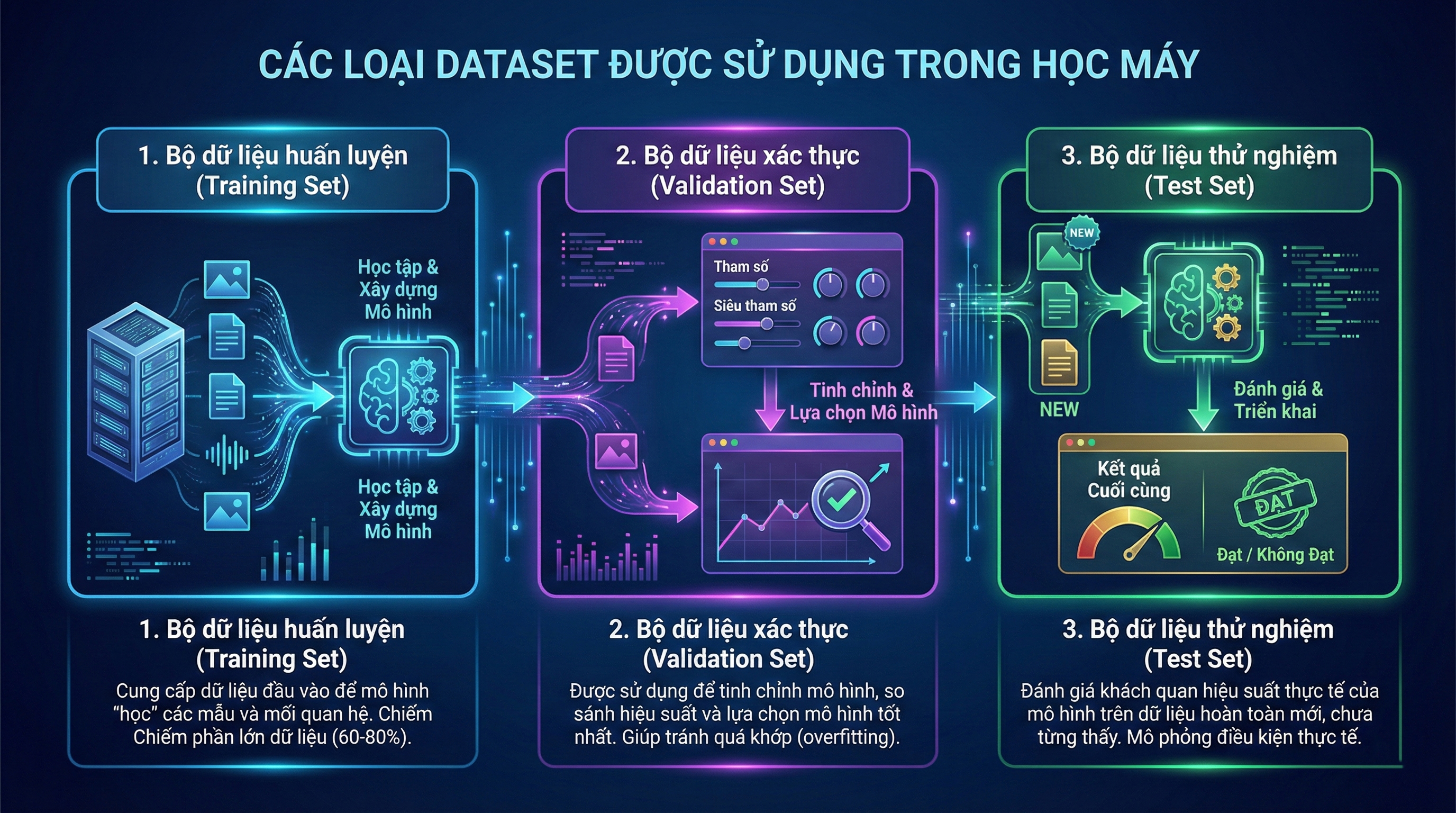
1. Bộ dữ liệu huấn luyện (Training Set)
Training set là tập dữ liệu dùng để dạy mô hình học tập các quy luật và mối quan hệ giữa dữ liệu đầu vào và đầu ra. Đây là nguồn “kiến thức nền” để thuật toán hiểu cách dự đoán, phân loại hoặc nhận dạng các mẫu mới.
Đặc điểm của training set:
-
Chiếm khoảng 60% – 70% tổng lượng dữ liệu.
-
Bao gồm đầy đủ features (đặc trưng) và labels (nhãn) trong các bài toán có giám sát.
-
Mô hình sẽ điều chỉnh các trọng số (weights) liên tục dựa trên sai số trong quá trình học.
Nói cách khác, training set chính là “giáo trình chính” để mô hình học máy hình thành khả năng suy luận.
2. Bộ dữ liệu xác thực (Validation Set)
Validation set là tập dữ liệu được dùng để đánh giá tạm thời mô hình trong quá trình huấn luyện và giúp lựa chọn cấu hình tốt nhất. Nó đóng vai trò là công cụ đo lường để xem mô hình có đang học đúng hay đang bị quá khớp (overfitting).
Chức năng của validation set:
-
Giúp kiểm tra độ chính xác theo từng giai đoạn huấn luyện.
-
Hỗ trợ tinh chỉnh hyperparameters như learning rate, số epoch, batch size…
-
Chiếm khoảng 10% – 20% tổng dataset.
Validation set là thành phần quan trọng giúp mô hình tìm được “điểm cân bằng” giữa khả năng học tốt và khả năng tổng quát hóa.
3. Bộ dữ liệu thử nghiệm (Test Set)
Test set là tập dữ liệu cuối cùng dùng để đánh giá hiệu suất thực sự của mô hình sau khi quá trình huấn luyện hoàn tất. Mục đích của test set là kiểm tra khả năng dự đoán của mô hình trên dữ liệu hoàn toàn mới mà nó chưa từng thấy trước đó.
Đặc điểm:
-
Chiếm khoảng 20% tổng dữ liệu.
-
Không được sử dụng trong quá trình huấn luyện hoặc tinh chỉnh mô hình.
-
Giúp kiểm chứng xem mô hình có thể hoạt động tốt trong môi trường thực tế hay không.
Test set giống như bài kiểm tra cuối kỳ: mô hình phải tự mình chứng minh khả năng mà không được “nhắc bài” từ dữ liệu huấn luyện.
Phân loại dataset theo đặc tính dữ liệu
Trong học máy, việc hiểu rõ đặc tính của từng dạng dữ liệu là yếu tố quan trọng giúp lựa chọn thuật toán phù hợp và tối ưu hiệu suất mô hình. Dataset thường được chia thành ba nhóm chính dựa trên đặc tính cấu trúc của dữ liệu: dữ liệu có cấu trúc, dữ liệu phi cấu trúc, và dữ liệu bán cấu trúc.
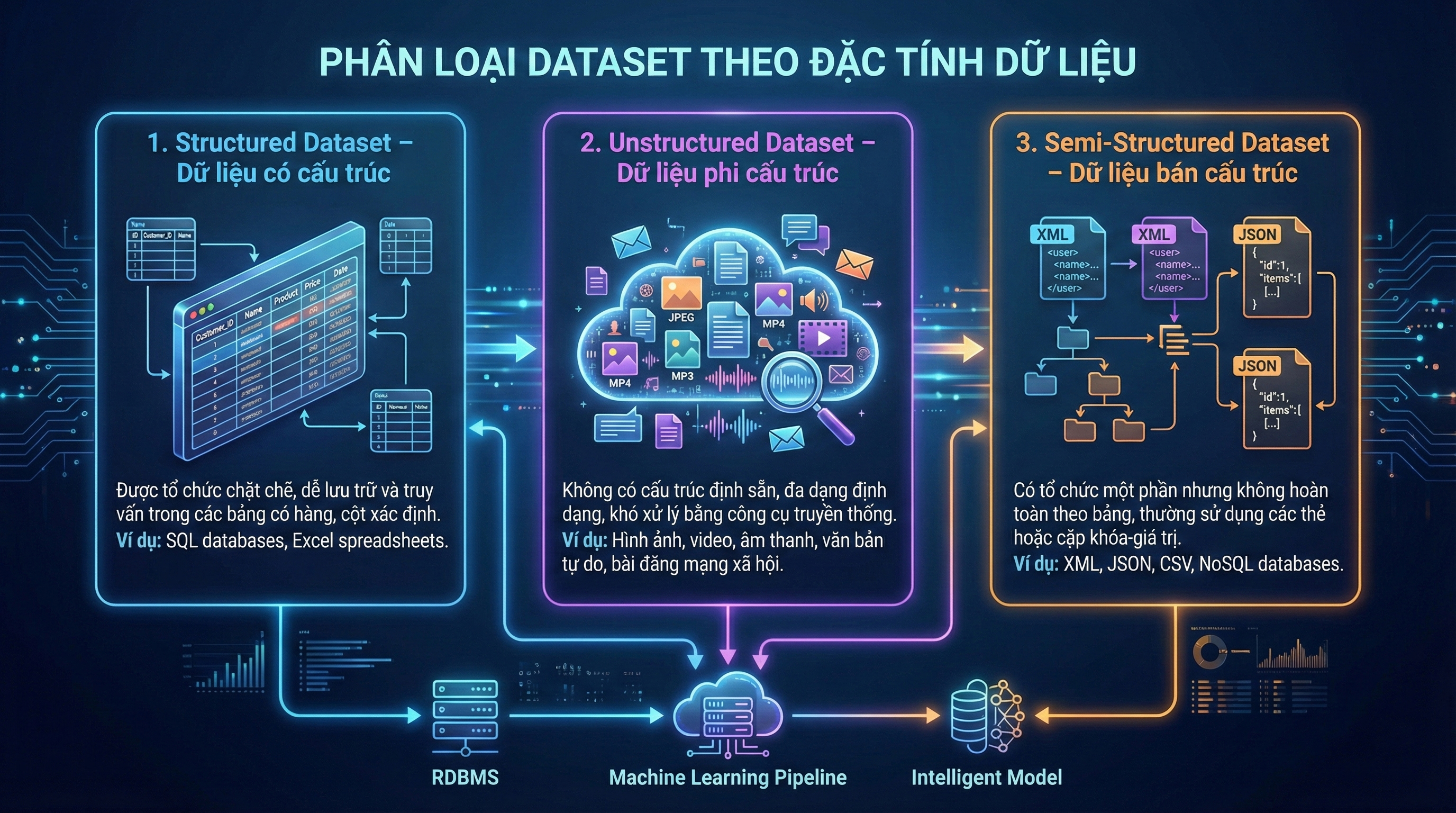
1. Structured Dataset – Dữ liệu có cấu trúc
Structured dataset là dạng dữ liệu được tổ chức một cách rõ ràng theo hàng và cột. Mỗi cột biểu diễn một thuộc tính cụ thể, trong khi mỗi hàng đại diện cho một bản ghi dữ liệu hoàn chỉnh. Do có khuôn dạng cố định, loại dữ liệu này rất dễ truy vấn, phân tích và xử lý.
Những hệ thống quản lý như SQL, Excel hay các bảng thống kê là ví dụ điển hình cho structured data. Dữ liệu khách hàng, báo cáo tài chính hay dữ liệu giao dịch thương mại điện tử đều thuộc nhóm này. Structured dataset rất phù hợp cho các mô hình học máy truyền thống và các bài toán phân tích dữ liệu doanh nghiệp.
2. Unstructured Dataset – Dữ liệu phi cấu trúc
Unstructured dataset là dạng dữ liệu không tuân theo bất kỳ khuôn mẫu bảng biểu nào. Chúng đa dạng về hình thức và thường xuất hiện dưới dạng văn bản, hình ảnh, video hoặc âm thanh. Do không có cấu trúc cố định, loại dữ liệu này đòi hỏi các phương pháp xử lý nâng cao như xử lý ngôn ngữ tự nhiên (NLP) hoặc mô hình học sâu (Deep Learning).
Ví dụ về unstructured data bao gồm: bình luận trên mạng xã hội, email, hình ảnh sản phẩm, video giám sát hoặc các bản ghi âm cuộc hội thoại. Đây là loại dataset phong phú nhất trong thời đại số, giúp mô hình AI phản ánh thế giới thực một cách toàn diện hơn.
3. Semi-Structured Dataset – Dữ liệu bán cấu trúc
Semi-structured dataset là dạng dữ liệu nằm giữa structured và unstructured. Chúng không có cấu trúc bảng rõ ràng, nhưng lại chứa các thẻ, nhãn hoặc metadata giúp mô tả nội dung, từ đó hỗ trợ việc xử lý và phân tích dữ liệu hiệu quả hơn.
Những định dạng như JSON, XML, hoặc log của máy chủ là ví dụ phổ biến. Dữ liệu trong các hệ thống IoT, API hoặc những dịch vụ web hiện đại cũng thường sử dụng dạng bán cấu trúc. Loại dữ liệu này linh hoạt, dễ mở rộng và phù hợp với các hệ thống phân tán hoặc xử lý dữ liệu lớn.
Các nguồn dataset dành cho học máy
Để xây dựng các mô hình học máy hiệu quả, việc tiếp cận những nguồn dữ liệu đáng tin cậy là vô cùng quan trọng. Dưới đây là những kho dataset uy tín và phổ biến nhất mà các nhà nghiên cứu, lập trình viên và kỹ sư AI thường sử dụng.
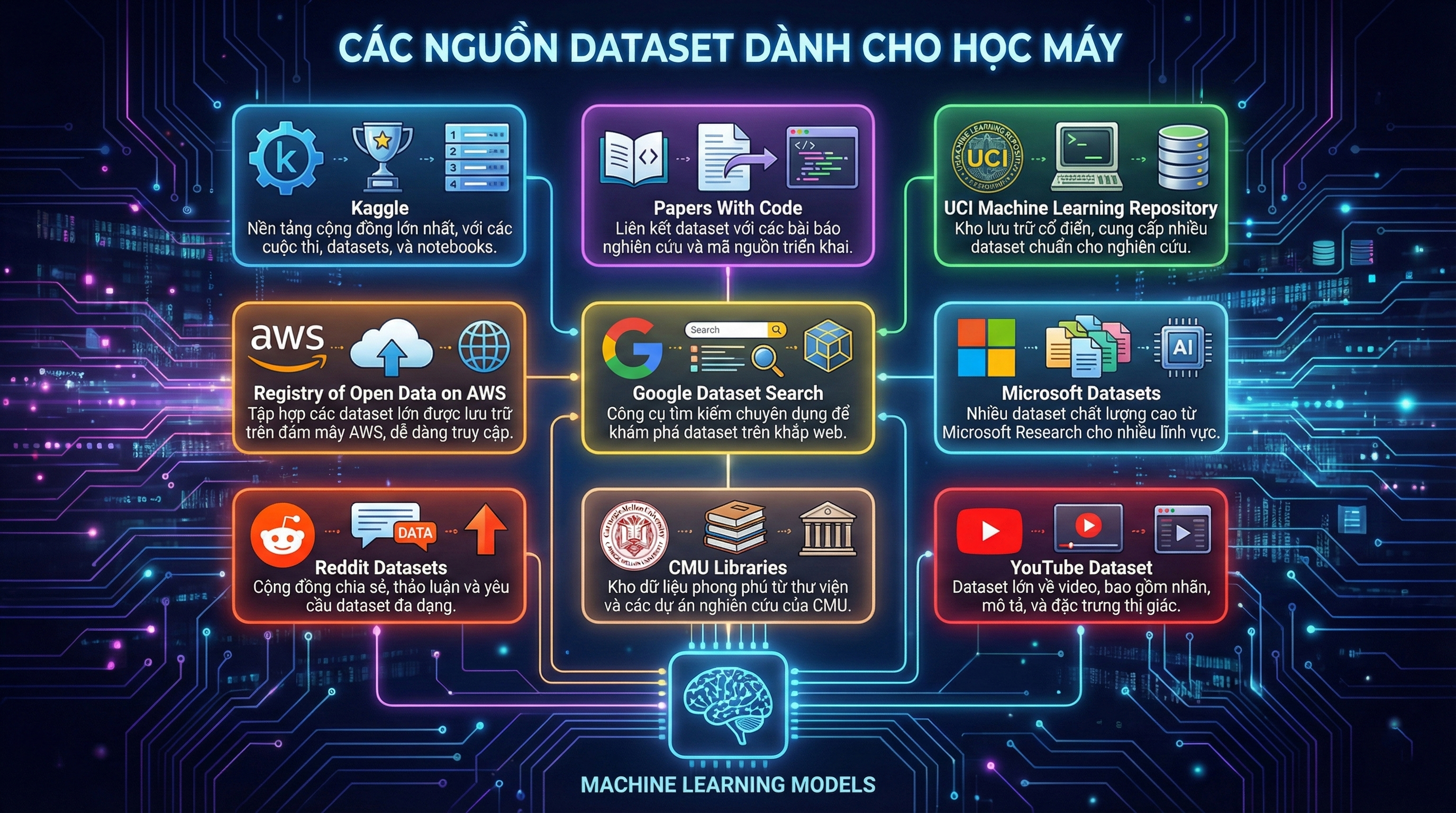
1. Kaggle
Kaggle là một trong những nền tảng nổi tiếng nhất khi nói đến dataset cho học máy. Với cộng đồng hàng triệu người dùng hoạt động liên tục, Kaggle cung cấp kho dữ liệu khổng lồ bao gồm hàng nghìn dataset thuộc nhiều chủ đề: kinh tế, y tế, tài chính, hình ảnh, xử lý ngôn ngữ tự nhiên…
Ngoài dữ liệu, Kaggle còn cung cấp notebook, hướng dẫn, các cuộc thi (competitions) và mã nguồn thực hành, rất phù hợp cho người mới lẫn chuyên gia. Tuy nhiên, do dữ liệu được cộng đồng đăng tải nên chất lượng không đồng đều, đòi hỏi người dùng phải kiểm tra và làm sạch trước khi sử dụng.
2. Papers With Code
Papers With Code là nền tảng kết nối giữa các bài báo nghiên cứu về học máy với mã triển khai tương ứng trên GitHub. Bên cạnh đó, trang cũng tổng hợp nhiều bộ dữ liệu liên quan đến thị giác máy tính, NLP, học sâu…
Điều tuyệt vời nhất của Papers With Code là bạn có thể xem một nghiên cứu, đọc code và tải dataset dùng trong bài báo chỉ trong vài cú nhấp chuột, giúp việc tiếp cận kiến thức mới trở nên rất trực quan.
3. UCI Machine Learning Repository
UCI Machine Learning Repository là một trong những kho dữ liệu lâu đời nhất trên Internet, được sử dụng rộng rãi trong nghiên cứu và giảng dạy. Kho dữ liệu này cung cấp hàng trăm dataset thuộc các lĩnh vực như y học, sinh học, hành vi con người, giáo dục…
Hầu hết dataset tại đây có kích thước nhỏ đến trung bình, thích hợp cho học thuật và thử nghiệm mô hình. Người dùng có thể tải xuống trực tiếp mà không cần đăng ký.
4. Registry of Open Data on AWS
Đây là nơi Amazon cung cấp các bộ dữ liệu mở dung lượng lớn, phục vụ cho nghiên cứu AI, dữ liệu lớn và điện toán đám mây. Tại đây, người dùng có thể dễ dàng tìm thấy dataset về hình ảnh vệ tinh, công nghệ sinh học, bản đồ, âm thanh và nhiều lĩnh vực chuyên sâu khác.
Kho dữ liệu trên AWS rất phù hợp cho những dự án yêu cầu xử lý quy mô lớn, đặc biệt khi kết hợp với hệ sinh thái cloud của Amazon.
5. Google Dataset Search
Google Dataset Search hoạt động giống như “công cụ tìm kiếm Google dành riêng cho dataset”. Người dùng có thể nhập từ khóa và tìm thấy các tập dữ liệu được xuất bản bởi các tổ chức uy tín như Harvard, WHO, các viện nghiên cứu hoặc các website chuyên ngành.
Điểm mạnh của công cụ này là khả năng tổng hợp nguồn dữ liệu phong phú từ nhiều trang khác nhau, tất cả đều có thể truy cập miễn phí.
6. Microsoft Datasets
Microsoft cung cấp nhiều bộ dữ liệu công khai phục vụ cho nghiên cứu về thị giác máy tính, NLP, nhận dạng giọng nói và các lĩnh vực liên quan đến AI. Dữ liệu từ Microsoft mang tính chính thống, sạch và được tổ chức khoa học, phù hợp cho cả doanh nghiệp lẫn học thuật.
Ngoài ra, Azure Open Datasets còn cung cấp các bộ dữ liệu được cập nhật thường xuyên, bao gồm thông tin khí tượng, dữ liệu từ cơ quan chính phủ Mỹ, dữ liệu thống kê và nhiều nguồn chính quy khác.
7. Reddit Datasets
Subreddit r/datasets là nơi cộng đồng chia sẻ các bộ dữ liệu mã nguồn mở thuộc mọi lĩnh vực: kinh tế, giáo dục, thể thao, khoa học, thói quen người dùng, văn hóa… Đây là nguồn dữ liệu phong phú và đa dạng, thích hợp cho việc khảo sát, nghiên cứu hành vi hoặc thử nghiệm mô hình mới.
8. CMU Libraries
Thư viện của Đại học Carnegie Mellon cung cấp các bộ dữ liệu mở về văn hóa, âm nhạc, nghệ thuật và lịch sử Hoa Kỳ. Nhiều dataset tại đây có tính độc đáo cao và không dễ tìm trên các nền tảng thông thường, rất thích hợp cho nghiên cứu chuyên sâu hoặc phân tích dữ liệu xã hội.
9. YouTube Dataset
YouTube cung cấp kho dữ liệu lớn bao gồm hàng triệu video được gắn nhãn theo hơn 4.700 lớp khác nhau. Dataset này bao gồm ba phần: tập huấn luyện, tập xác nhận và tập kiểm tra.
Các video được phân loại theo 24 chủ đề: trò chơi, giải trí, giáo dục, thể thao, ẩm thực, nghệ thuật… Đây là nguồn dữ liệu cực kỳ giá trị cho các dự án thị giác máy tính hoặc nhận dạng nội dung video.
Các lưu ý khi sử dụng dataset trong học máy
Việc sử dụng dataset trong học máy không chỉ đơn giản là tải dữ liệu về và đưa vào mô hình. Để đảm bảo kết quả chính xác và mô hình hoạt động ổn định, bạn cần tuân thủ một số nguyên tắc và lưu ý quan trọng dưới đây.
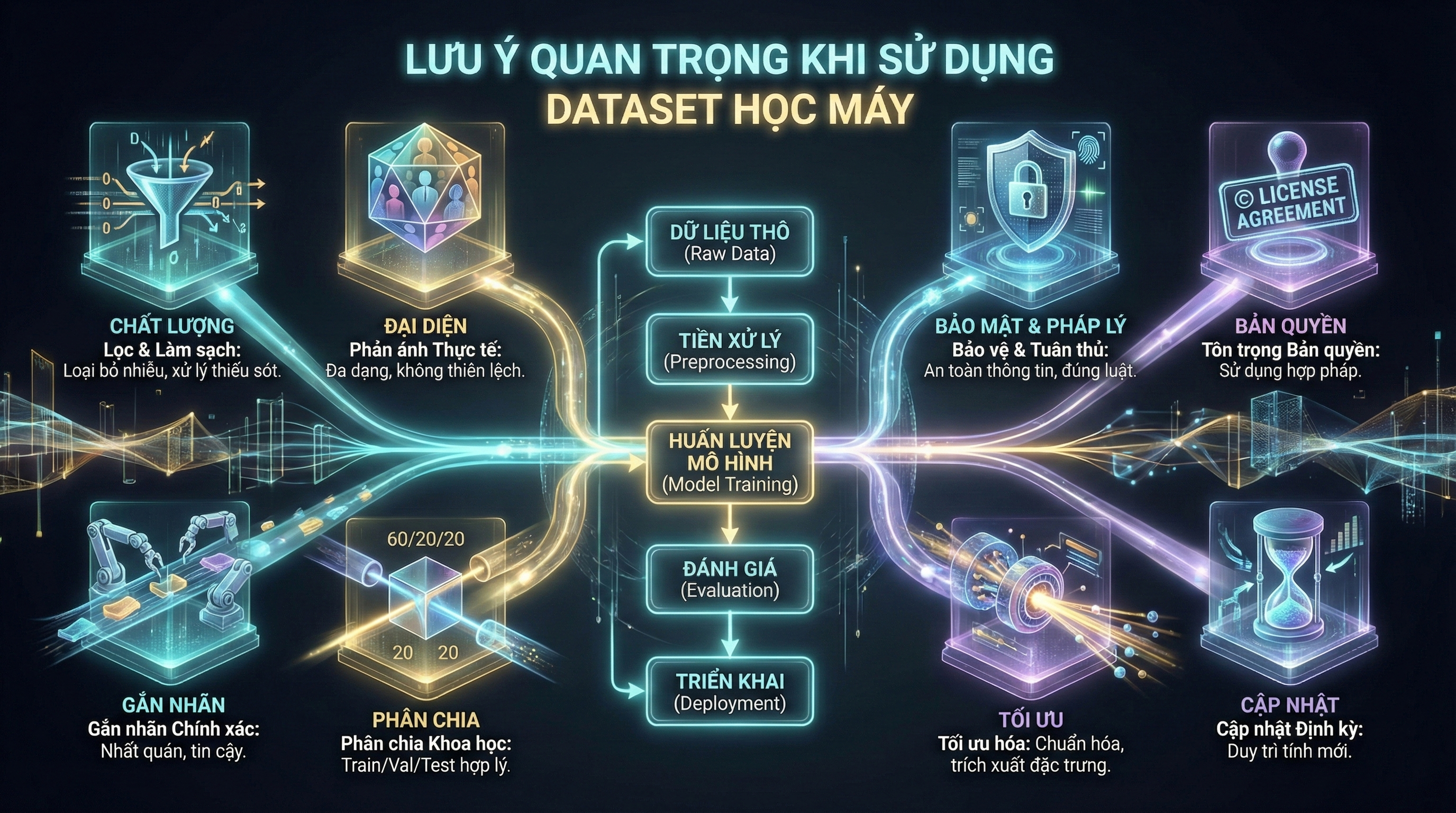
1. Đảm bảo chất lượng dữ liệu (Data Quality)
Dữ liệu càng sạch, mô hình càng chính xác. Vì vậy, trước khi đưa dataset vào huấn luyện, bạn cần:
-
Loại bỏ dữ liệu bị thiếu, trùng lặp hoặc sai định dạng.
-
Kiểm tra dữ liệu lỗi, nhiễu hoặc giá trị ngoại lai (outliers).
-
Chuẩn hóa và thống nhất kiểu dữ liệu cho từng cột.
Một dataset chất lượng thấp sẽ khiến mô hình học sai, dẫn đến dự đoán lệch lạc.
2. Kiểm tra tính đại diện của dữ liệu (Data Representativeness)
Dataset phải phản ánh đúng môi trường thực tế mà mô hình sẽ hoạt động. Điều này bao gồm:
-
Dữ liệu đa dạng, bao phủ đầy đủ các trường hợp.
-
Không tập trung quá nhiều vào một nhóm, đối tượng hoặc tình huống.
-
Hạn chế thiên lệch (bias) trong dữ liệu.
Tính đại diện tốt giúp mô hình tổng quát hóa tốt hơn thay vì chỉ hoạt động đúng trên dữ liệu huấn luyện.
3. Gắn nhãn đúng và nhất quán (Label Accuracy)
Đối với học máy có giám sát (supervised learning), nhãn (label) quyết định trực tiếp đến hiệu quả mô hình. Vì vậy:
-
Đảm bảo nhãn được gắn chính xác.
-
Tránh nhãn thiếu nhất quán giữa các mẫu dữ liệu.
-
Kiểm tra lại nhãn bằng nhiều phương pháp, đặc biệt với dữ liệu thủ công.
Nhãn sai → mô hình học sai → hiệu suất giảm mạnh.
4. Phân chia hợp lý giữa Training – Validation – Testing
Một sai lầm phổ biến là chia dữ liệu không đúng dẫn đến mô hình bị “học thuộc” (overfitting). Tỷ lệ được khuyến nghị:
-
Training set: 60% – 70%
-
Validation set: 10% – 20%
-
Testing set: 20%
Việc phân tách chuẩn xác giúp đánh giá mô hình khách quan hơn.
5. Bảo mật và tuân thủ pháp lý (Data Privacy & Compliance)
Nếu dataset có chứa dữ liệu cá nhân hoặc dữ liệu nhạy cảm, bạn cần đảm bảo:
-
Tuân thủ các quy định về bảo mật (GDPR, HIPAA…).
-
Tránh lộ thông tin định danh cá nhân (PII).
-
Chỉ sử dụng dữ liệu được phép chia sẻ và khai thác.
Vi phạm bảo mật dữ liệu có thể gây thiệt hại lớn cho doanh nghiệp.
6. Chú ý tới bản quyền và giấy phép sử dụng
Không phải dataset nào cũng miễn phí hoặc cho phép dùng cho mục đích thương mại. Bạn cần:
-
Kiểm tra điều khoản (license) của dataset.
-
Tôn trọng quyền sở hữu trí tuệ.
-
Tránh sử dụng dữ liệu không rõ nguồn gốc.
Điều này rất quan trọng khi phát triển sản phẩm thương mại hóa.
7. Tối ưu dữ liệu trước khi huấn luyện (Data Preprocessing)
Dữ liệu thô thường không phù hợp để đưa vào mô hình. Bạn cần:
-
Chuẩn hóa (normalization) hoặc tiêu chuẩn hóa (standardization).
-
Chuyển đổi dữ liệu văn bản sang dạng vector.
-
Cân bằng dữ liệu (nếu lệch lớp).
-
Trích chọn đặc trưng (feature selection).
Preprocessing giúp tăng tốc độ huấn luyện và cải thiện độ chính xác.
8. Cập nhật dữ liệu định kỳ
Mô hình có thể lỗi thời nếu dataset không còn phản ánh đúng thực tế. Bởi vậy:
-
Nên cập nhật dataset theo chu kỳ.
-
Huấn luyện lại mô hình khi dữ liệu thay đổi mạnh.
-
Theo dõi độ chính xác để biết khi nào cần refresh dữ liệu.
Dataset càng cập nhật thường xuyên → mô hình càng thông minh và ổn định.
Dataset là nền tảng của mọi mô hình học máy. Vì vậy, việc chọn đúng dữ liệu, làm sạch dữ liệu và kiểm soát chất lượng dữ liệu là yếu tố quyết định thành công của toàn bộ dự án AI.

Lời kết
Dataset đóng vai trò trung tâm trong toàn bộ quy trình phát triển học máy và trí tuệ nhân tạo. Một mô hình chỉ thực sự hoạt động hiệu quả khi được huấn luyện trên bộ dữ liệu chất lượng, đầy đủ và có tính đại diện cao. Từ việc thu thập, làm sạch, gắn nhãn cho đến phân chia dữ liệu thành training – validation – testing, mỗi bước đều ảnh hưởng trực tiếp đến khả năng dự đoán và độ chính xác của mô hình.
Thông qua bài viết này, bạn đã hiểu rõ dataset là gì, các loại dataset trong học máy, những nguồn dataset phổ biến, cũng như những lưu ý quan trọng khi sử dụng dữ liệu. Việc lựa chọn đúng dataset ngay từ đầu không chỉ giúp tối ưu hiệu suất mô hình mà còn tiết kiệm thời gian, chi phí và công sức trong toàn bộ vòng đời phát triển dự án AI.
Trong bối cảnh dữ liệu ngày càng trở thành tài nguyên quý giá, những ai nắm vững cách làm việc với dataset sẽ có lợi thế lớn trong ngành công nghệ và khoa học dữ liệu. Hãy tiếp tục khám phá, thực hành và thử nghiệm nhiều loại dữ liệu khác nhau để mở rộng kỹ năng và tạo ra những mô hình AI mạnh mẽ, thực tiễn hơn.

